MaxFrame 多模态音视频算子开发实践#
背景信息#
随着多模态大模型和语音智能应用的快速发展,音频数据正成为模型训练与内容理解的重要数据来源。无论是语音识别、字幕生成、语音内容检索,还是训练语料构建,都需要先从海量原始音频中高效提取文本信息。
但在实际业务中,音频文件通常分散存放在不同位置,格式、时长和质量也不尽相同,难以直接用于后续处理。传统方式往往需要先完成音频下载,再借助多个独立工具进行转码、识别和结果整理,整体流程较为分散,在大规模处理场景下容易出现效率低、开发复杂和运维成本高等问题。
MaxCompute 提供 Data+AI 一体化能力,通过分布式计算框架 MaxFrame,支持对音频数据进行统一调度与批量处理。用户可以基于 MaxFrame 构建从音频下载到语音识别的完整处理链路,对海量原始音频进行自动化转写,并将识别结果输出为结构化数据,便于后续分析、检索和模型训练使用。
适用场景#
语音内容转录:适用于播客、课程录音、访谈、会议音频等内容的批量转写,便于后续归档、检索和内容消费。
字幕生成与文本提取:适用于对音视频中的音轨进行识别,生成字幕文本或提取语音内容。
训练数据准备:适用于从原始音频中批量提取文本,为语音识别、语音理解等模型训练准备基础语料。
业务录音结构化处理:适用于客服录音、服务通话、业务访谈等场景,将非结构化音频内容转化为可分析的文本数据。
核心流程说明#
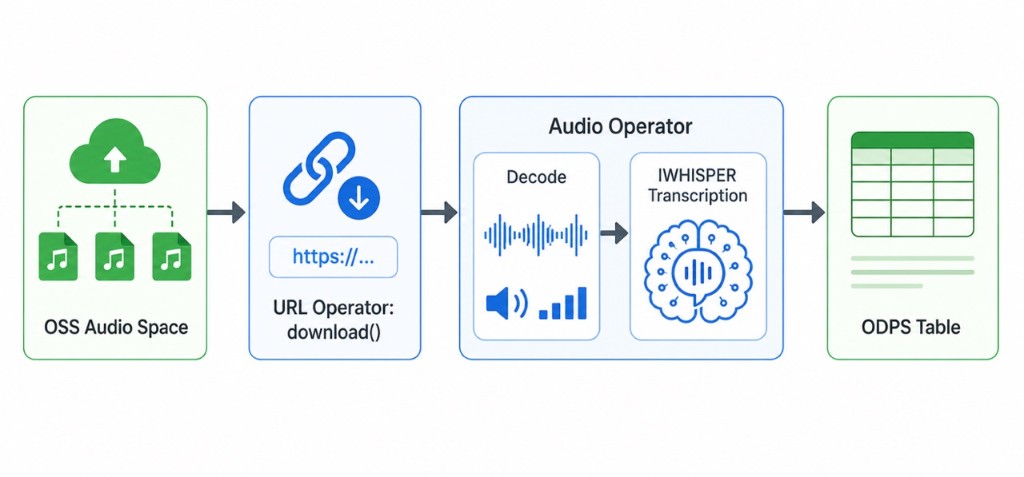
前提条件#
# |
条件 |
说明 |
|---|---|---|
1 |
开通 MaxCompute |
需要一个已开通的 MaxCompute 项目,并具备有效的 Access ID / Access Key。 |
2 |
开通 DPE 引擎 |
|
3 |
上传音频至 OSS |
原始音频文件已上传至目标 OSS Bucket。 |
4 |
OSS RAM 角色授权 |
为 |
5 |
MaxFrame SDK 版本 |
请使用 MaxFrame SDK 2.7.0 及以上版本( |
配置 OSS RAM 角色授权#
使用 .url.download(storage_options={"role_arn": ...}) 时,MaxFrame 会通过 RAM 角色读取 OSS 数据。请确保:
该角色具备 OSS 读权限(例如
AliyunOSSReadOnlyAccess)。该角色的信任策略允许 MaxCompute 服务扮演该角色。
环境准备#
MaxCompute 参数占位:
ODPS_ACCESS_ID = "<REDACTED_ACCESS_ID>"
ODPS_ACCESS_KEY = "<REDACTED_ACCESS_KEY>"
ODPS_PROJECT = "<REDACTED_PROJECT>"
ODPS_ENDPOINT = "<REDACTED_ENDPOINT>"
OUTPUT_TABLE = "<REDACTED_OUTPUT_TABLE>"
OSS 参数占位:
ROLE_ARN = "<REDACTED_ROLE_ARN>"
OSS_ENDPOINT = "<REDACTED_OSS_ENDPOINT>"
OSS_BUCKET_NAME = "<REDACTED_OSS_BUCKET_NAME>"
OSS_DATA_PREFIX = "<REDACTED_OSS_DATA_PREFIX>"
完整代码参考#
初始化 ODPS 与 MaxFrame Session:
import maxframe
assert maxframe.__version__ >= "2.7.0", (
f"maxframe >= 2.7.0 is required, current version: {maxframe.__version__}. "
f"Please run: pip install --upgrade maxframe"
)
print(f"maxframe version: {maxframe.__version__} ✓")
import pandas as pd
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
from odps import ODPS
o = ODPS(
access_id=ODPS_ACCESS_ID,
secret_access_key=ODPS_ACCESS_KEY,
project=ODPS_PROJECT,
endpoint=ODPS_ENDPOINT,
)
options.sql.enable_mcqa = False
options.dag.settings = {"engine_order": ["DPE"]}
session = new_session(o)
print(f"Session ID : {session.session_id}")
print(f"LogView : {session.get_logview_address()}")
构建 OSS 音频 URL 列表:
file_names = ["audio_011.flac"]
audio_urls = [
f"oss://{OSS_ENDPOINT}/{OSS_BUCKET_NAME}/{OSS_DATA_PREFIX}{name}"
for name in file_names
]
print(f"Processing {len(audio_urls)} audio files:")
for u in audio_urls:
print(f" - {u}")
使用 .audio 算子进行解码、语言检测、语音转写与 VAD:
df = md.DataFrame(pd.DataFrame({"name": file_names, "url": audio_urls}))
# Download OSS audio as bytes via RAM role
df["audio_bytes"] = df["url"].url.download(
storage_options={"role_arn": ROLE_ARN},
errors="raise",
)
# Decode to target sample rate
df["decoded"] = df["audio_bytes"].audio.decode(target_sample_rate=16000)
# Basic properties
df["sample_rate"] = df["decoded"].audio.sample_rate
df["duration"] = df["decoded"].audio.duration
df["format"] = df["decoded"].audio.format
# Language detection
df["language"] = df["audio_bytes"].audio.detect_language(
max_duration_sec=30.0,
cpu=4,
memory="16GiB",
)
# Speech-to-text
transcribed = df["audio_bytes"].audio.transcribe(cpu=4, memory="16GiB")
df["text"] = transcribed["text"]
# Voice activity detection
df["vad"] = df["audio_bytes"].audio.vad_detect(threshold=0.5)
result_df = df[[
"name",
"sample_rate",
"duration",
"format",
"language",
"text",
"vad",
]]
md.to_odps_table(result_df, OUTPUT_TABLE, overwrite=True).execute()
print(result_df.execute().fetch())
资源清理:
session.destroy()
核心技术亮点#
URL 直通 OSS 音频:通过
.url.download()直接处理 OSS 音频,无需依赖 Object Table。内置分布式音频算子:支持 decode、元信息、语言检测、转写与 VAD。
灵活的资源控制:可通过算子与引擎参数适配 CPU/GPU 风格负载。
低运维成本:复用 MaxCompute 弹性计算与存储体系。
常见问题排查#
OSS 访问被拒绝#
现象:调用 .url.download(storage_options={"role_arn": ...}) 时报访问被拒绝错误。
原因:角色权限配置错误或缺失。
解决方案:请逐一确认以下事项:
Role ARN 正确 — 确认
storage_options中的role_arn值与阿里云控制台配置的 RAM 角色一致。OSS 读权限 — 确认 RAM 角色已附加
AliyunOSSReadOnlyAccess策略(或等效自定义策略),具备目标 Bucket 的oss:GetObject权限。